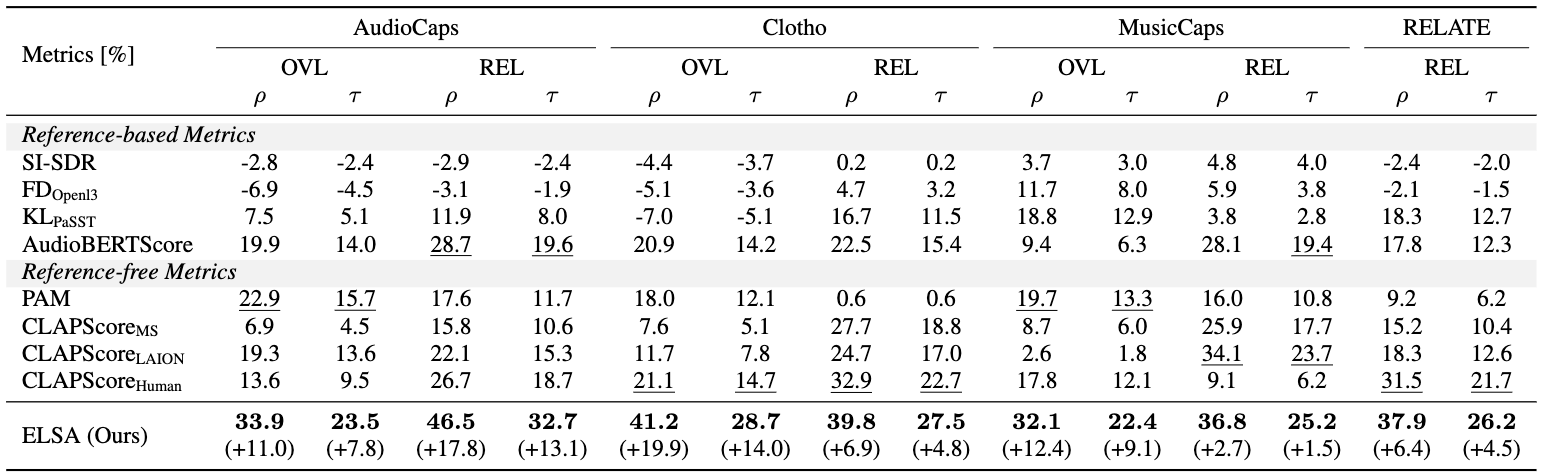
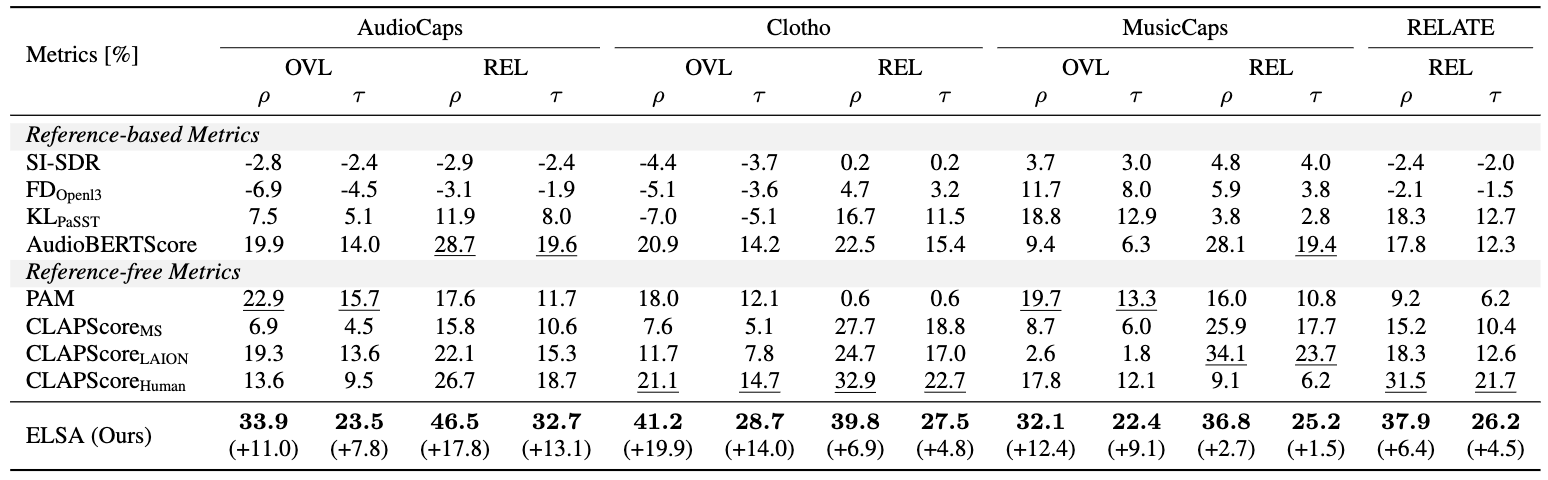
Table 1: Correlation with human ratings across AudioCaps, Clotho, MusicCaps, and RELATE.
ELSA consistently achieves the highest rank-correlation, improving Kendall's tau on REL by +13.1, +4.8,
+1.5, and +4.5 points over the strongest baseline.
Table 2: Compositional benchmark results on RELATE (IS/OS) and CompA (attribute/order).
ELSA outperforms baselines on RELATE and wins 3 out of 4 CompA evaluation settings, showing stronger
event-level compositional alignment.
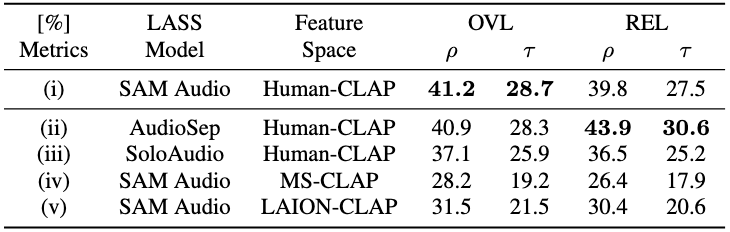
Table 3: Component ablation on Clotho. Performance changes are relatively small across
LASS variants, while changing the text-audio embedding space causes much larger drops, indicating ELSA is
more sensitive to embedding quality than separator choice.
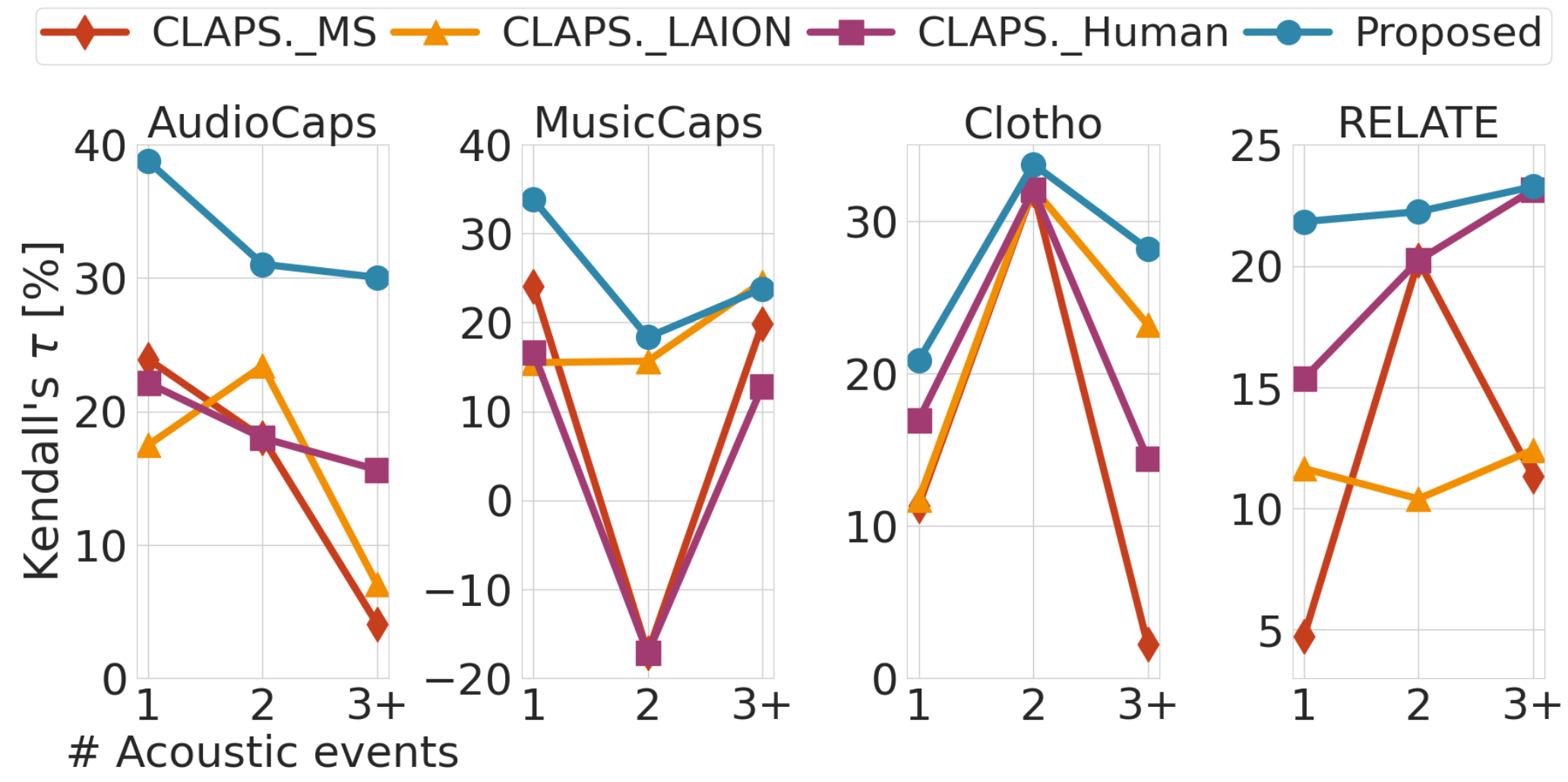
Figure 3: Sensitivity analysis of metric-REL correlation with respect to the number of
acoustic events in the text query. ELSA maintains stronger correlation than CLAPScore variants across
different event counts, indicating robust fine-grained alignment.
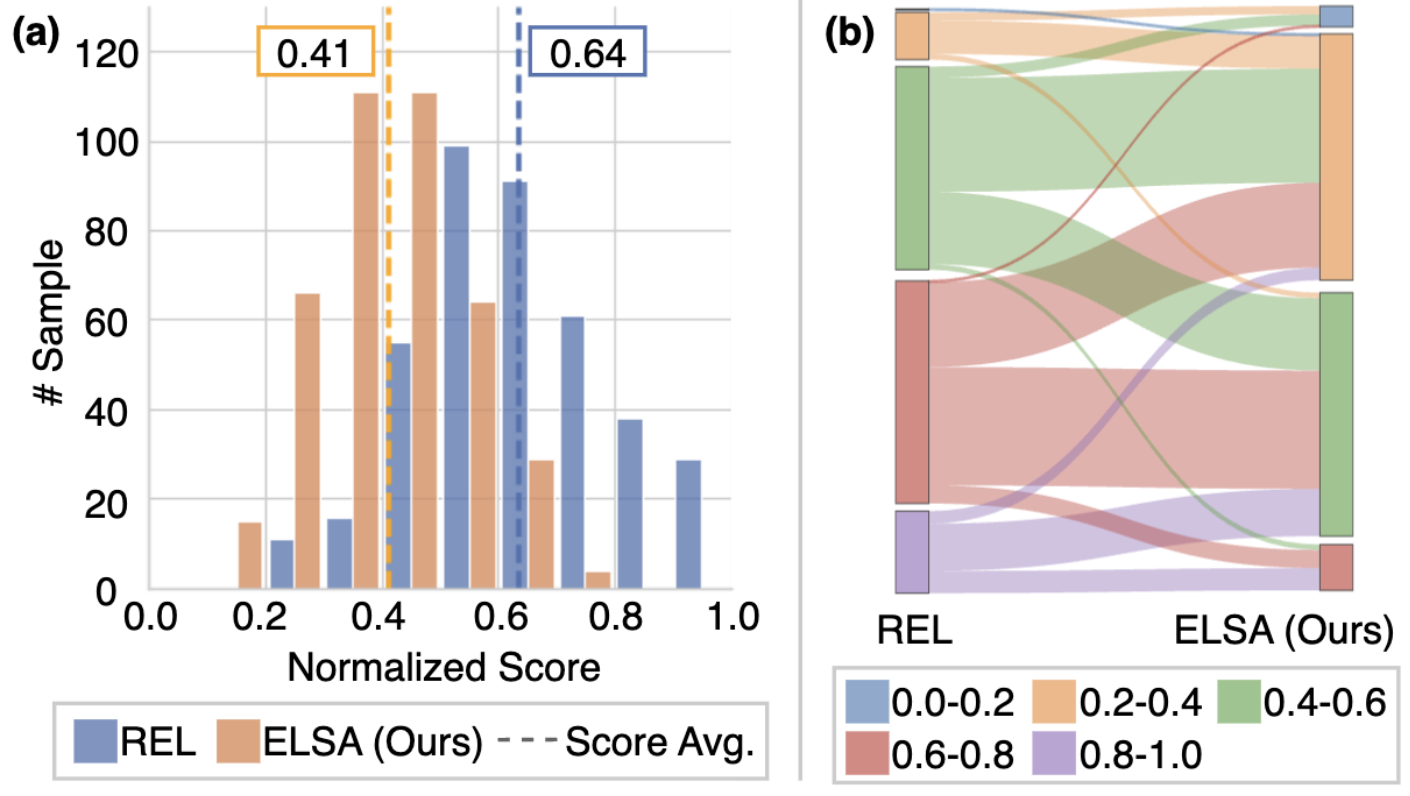
Figure 4: Relationship between REL and ELSA on AudioCaps. ELSA follows REL's rank
tendency but with a lower score scale, reflecting stricter event-level evaluation than coarse global
matching.
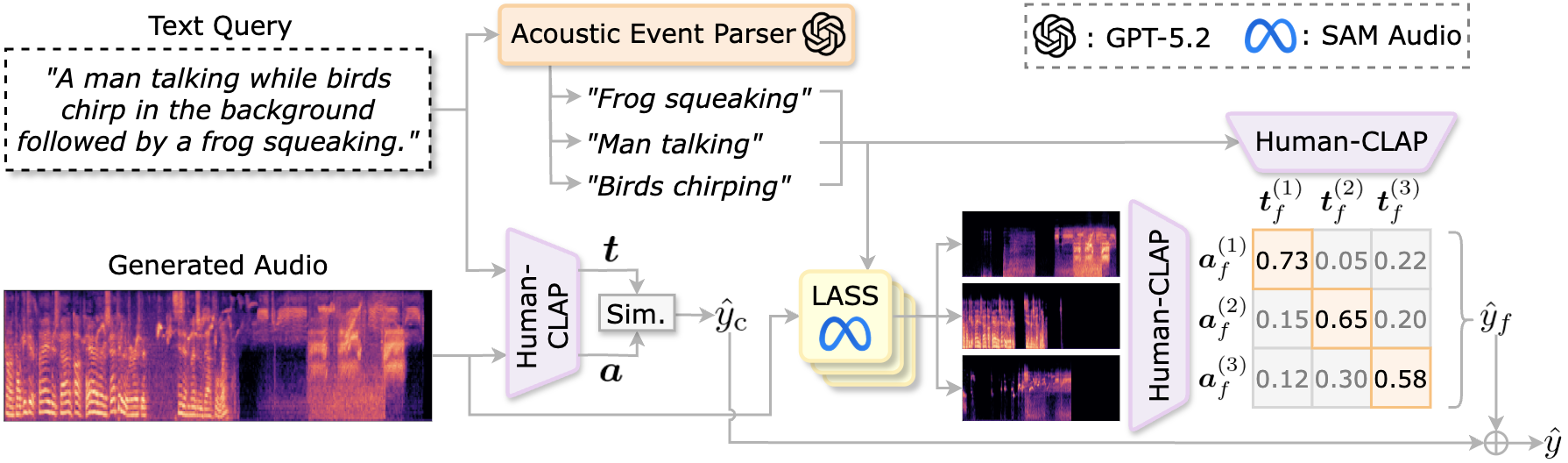
 Acoustic
Acoustic LASS
LASS